Bengali Handwritten Grapheme Classification
src: https://github.com/SumonKantiDey/Draw-Grapheme
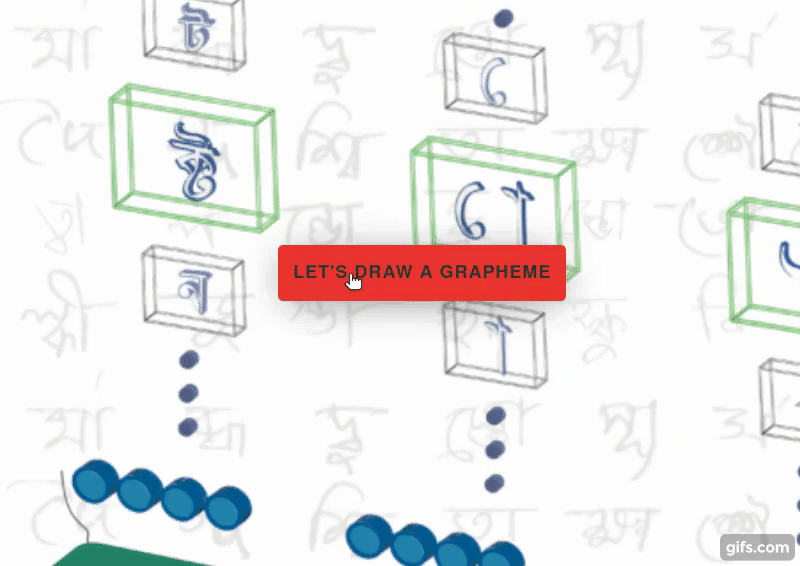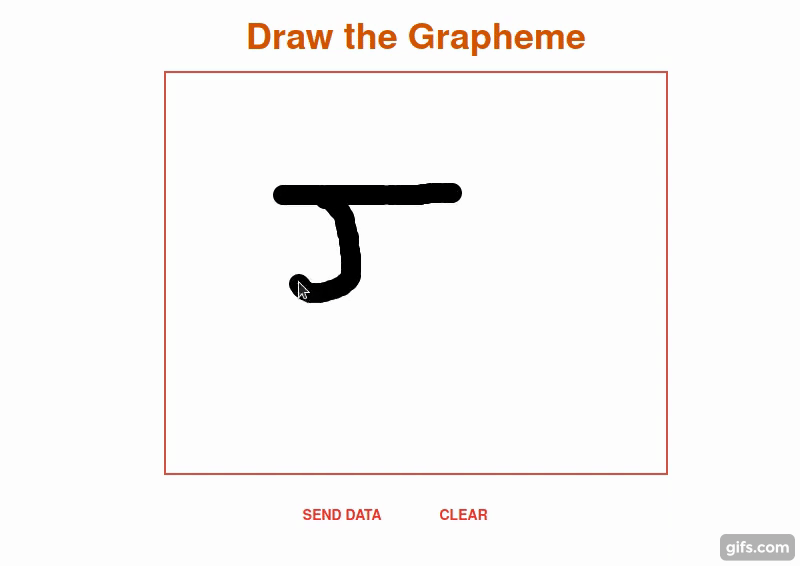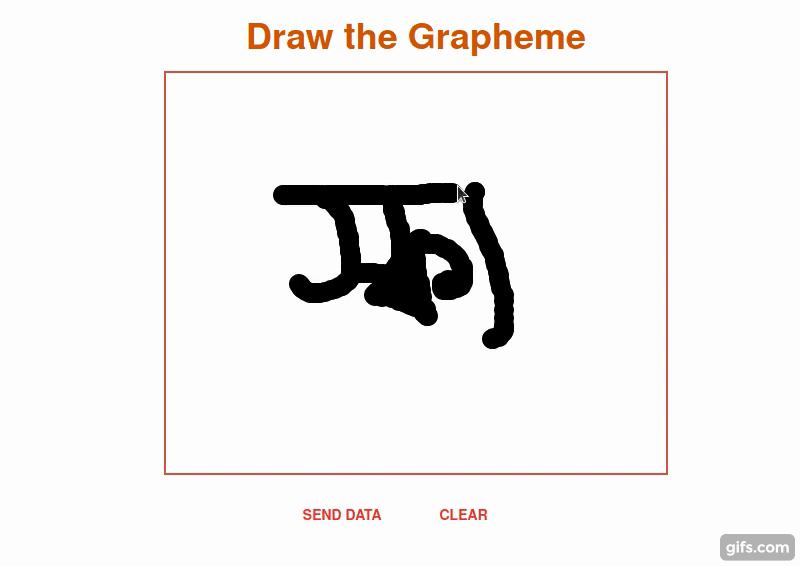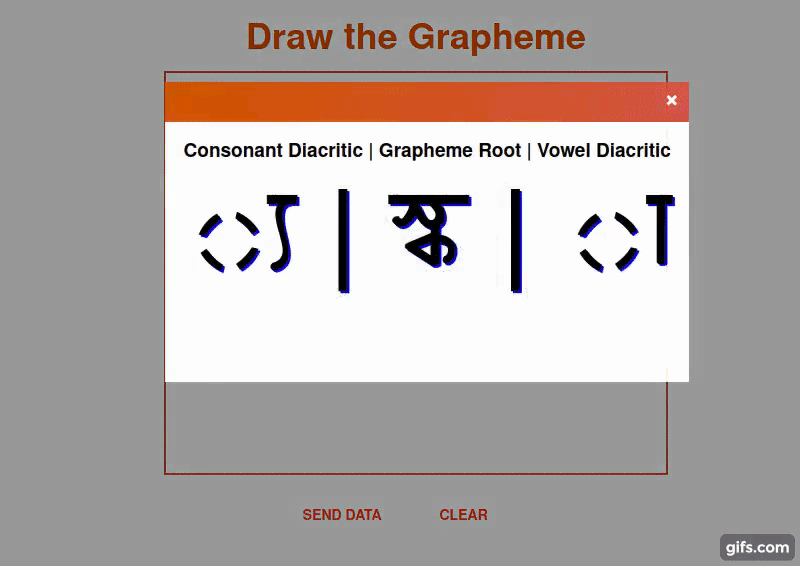
Bengali is the 5th most spoken language in the world with hundreds of millions of speakers. Bengali has 49 letters (to be more specific 11 vowels and 38 consonants) in its alphabet, there are also 18 potential diacritics or accents. This means that there are many more graphemes or the smallest units in a written language. The added complexity results in ~13,000 different grapheme variations (compared to English’s 250 graphemic units). In this yerar Bengali.ai host a competition Bengali.AI Handwritten Grapheme Classification the target of this competition is to classify handwritten characters of the Bengali alphabet which is broken down into three components for each grapheme, or character: 1.the root, 2.the vowel diacritic, 3. the consonant diacritic.
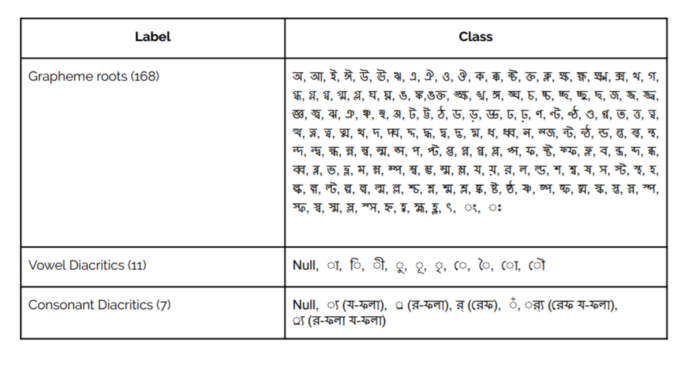
img src: www.kaggle.com/c/bengaliai-cv19/discussion/122421
This is the Baseline Model Notebook for that multi-class classification problem. Where I have made a typical CNN network, which stacks a few convolutional layers, then a pooling layers. Also, BatchNormalization, Dropouts and ReduceLROnPlateau are added to elevate the stability of the model.
For demoing this bengali handwritten grapheme classification problem I have made this Flask webapp which will load the pretrained weight of the model and take the grapheme as input and return three components (root, vowel diacritic, consonant diacritic) of the grapheme. To konw more about this webapp click here.